主题
视频源规则
规则格式:
在规则中,除了源Url、源名称、源分组、请求头、搜索地址、发现Url筛选规则、Url正则 这几项是固定格式外,其他项都支持Jsoup格式规则和XPath格式规则,一个视频源中可以同时使用两种格式,哪种容易取值就使用哪种,讲究的就是一个自由选择
支持的规则类型
- XPath 【跳转到 XPath 教程位置】
- Jsoup 【跳转到 Jsoup 教程位置】
XPath规则教程
ℹ️ 什么是 XPath ?
XPath 是一种用在 XML 文档中定位元素的语言,同样也支持 HTML 元素的解析,所谓 XPath,是指 XML path language。path 就是路径,那么 XPath 主要是通过路径来查找元素。
首先从下面一张图来了解一下HTML中的结构:
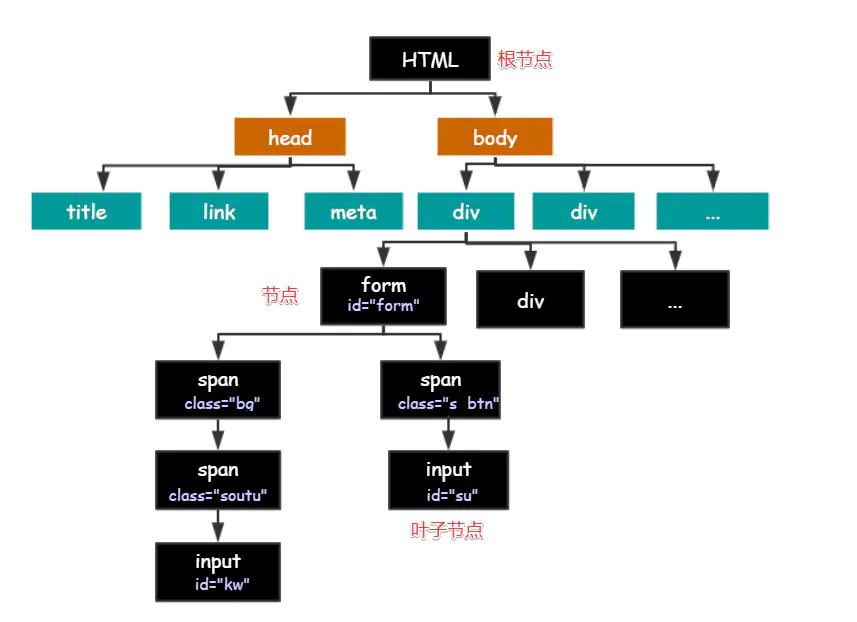
HTML 的结构就是树形结构,HTML 是根节点,所有的其他元素节点都是从根节点发出的。其他的元素都是这棵树上的节点 Node,每个节点还可能有属性和文本。 而路径就是指某个节点到另一个节点的路线。
XPath 中的绝对路径从 HTML 根节点开始算,相对路径从任意节点开始。
视频源规则采用相对路径定位模式,以 // 开头,相对路径可以从任意节点开始,一般我们选取一个可以唯一定位到的元素开始写即可。
基本定位语法
| 表达式 | 说明 | 举例 |
|---|---|---|
| / | 从当前节点开始选取 | /html/div/span |
| // | 从任意节点开始选取 | //input |
| . | 选取当前节点 | |
| .. | 选取当前节点的父节点 | ///input/.. 会选取 input 的父节点 |
| @ | 选取属性,或者根据属性选取 | //input[@data] 选取具备 data 属性的 input 元素 //@data 选取所有 data 属性或者输出data的值 |
| * | 通配符,表示任意节点或任意属性 | |
| text() | 文本匹配,表示取当前节点的文本内容 | //h1/text() |
元素属性定位
属性定位是通过 @ 符号指定需要使用的属性。
- 根据元素具备的某个属性查找元素
//img[@data-original]选取包含data-original属性的所有img。可以定位到以下元素:
html
<img src='' data-original='图片地址' />- 根据属性值查找元素
//img[@class='aclass']选取属性 class 值为 aclass 的所有节点。可以定位到以下元素:
html
<img src='' class='aclass' />使用谓语定位
谓语是 XPath 中用于描述元素位置。主要有数字下标、最后一个子元素last()、元素下标函数position()。
- 使用下标的方式,从 ul 找到第二个 li 里面的 span :
//ul[@class='ul']/li[2]/span💡 提示
XPath 中的下标从 1 开始。
- 查找最后一个子元素,选取 ul 下的最后一个 li:
//ul[@class='ul']/li[last()]- 查找倒数第二个子元素,选取 ul 下的最后一个 li:
//ul[@class='ul']/li[last()-1]- 使用 position() 函数,选取 ul 下的第二个 li:
//ul[@class='ul']/li[position()=2]- 使用 position() 函数,选取下标大于2的 li:
//ul[@class='ul']/li[position()>2]使用逻辑运算符
如果元素的某个属性无法精确定位到这个元素,我们还可以用逻辑运算符进行定位
and
查找 name 属性等于 a 并且 class 属性等于 aclass 的任意元素
//*[@name='a' and @class='aclass']or
查找 name 属性等于 a 或者 class 属性等于 aclass 的任意元素,满足其中一个条件即可
//*[@name='a' or @class='aclass']|
返回 name 属性等于 a 和 class 属性等于 aclass 的所有元素节点集
//*[@name='a'] | //*[@class='aclass']条件定位
| 函数 | 说明 | 实例 |
|---|---|---|
| contains | 属性或文本中包含某些字符 | //div[contains(@class,'aclass')] 选取 class 属性包含aclass的div元素 //div[contains(text(),'H3')] 选取内部文本包含H3的div元素 |
| not | 不包含 | //li[not(@data)] 选取不包含@data属性的li元素 |
| starts-with | 属性或文本以某些字符开头 | //div[starts-with(@id, 'data')] 选取 id 属性以 data 开头的 div 元素 //div[starts-with(text(), 'H3')] 选取内部文本以H3开头的 div 元素 |
| ends-with | 属性或文本以某些字符结尾 | //div[ends-with(@id, 'data')] 选取 id 属性以 data 结尾的 div 元素 //div[ends-with(text(), 'H3')] 选取内部文本以H3结尾的 div 元素 |
层级属性结合定位
遇到某些元素无法精确定位的时候,可以查找其父级及其祖先节点,找到有确定的祖先节点后通过层级依次向下定位。
html
<div class="video-info">
<div class="video-info-items">
<span class="video-info-itemtitle">评分:</span>
<div class="video-info-item"><font color="#007711">7.0分</font></div>
</div>
</div- 根据层级向下找,从 class 值为 video-info 的 div 找到 font:
//div[@class='video-info']/div/div/font- 查找某元素内部的所有元素,选取 class 值为 video-info 的 div 元素内部的所有 div
//div[@class='video-info']//div说明
第二个双斜杠,表示无视层级关系,选取内部所有的 div
- 查找上级节点和同级节点
查找上级节点,最后的/..就是查找span的上级节点,再上一级,就需要再添加一个/..
//span/..查找同级节点,树形结构中,同级节点之间的关系是通过上级节点建立起来的。所以可以先找到上级节点,再通过上级节点找同级节点。
上面代码中,若我们想通过 span 元素查找同级的 div 元素
//span/../div文本定位综合条件判断
html
<div class="video-info">
<div class="video-info-items">
<span class="video-info-itemtitle">导演:</span>
<div class="video-info-item"><a href=''>导演A</a> <a href=''>导演B</a></div>
</div>
<div class="video-info-items">
<span class="video-info-itemtitle">连载:</span>
<div class="video-info-item">更新到第10集</div>
</div>
<div class="video-info-items">
<span class="video-info-itemtitle">备注:</span>
<div class="video-info-item">HDTC</div>
</div>
<div class="video-info-items">
<span class="video-info-itemtitle">评分:</span>
<div class="video-info-item">
<font color="#007711">7.0分</font>
</div>
</div>
</divXPath中取得文本的函数有text()或者string(),一般多使用text()
| 函数 | 说明 |
|---|---|
| /text() | 匹配文本,取得当前节点的文本内容 |
| //text() | 取得当前节点和子节点的所有文本内容 |
| substring-after(string, string) | 在第一个文本中截取第二个文本之后的部分 |
| substring-before(string, string) | 在第一个字符串中截取第二个字符串之前的部分 |
例如上面代码,我们要取得导演A和导演B的文本,先用文本判断文本内容为 导演: 的那个 span 元素,然后再根据 span 元素取上级节点,再从上级节点取得包含导演数据那个 div
//span[text()='导演:']/../div//text()上面规则末尾使用了 //text() 而不是 /text(),为什么呢?
原因就是 div 节点内还有 a 元素节点,导演文本数据是在 a 节点内,所以使用 //text(),当然也可以使用下面的规则:
html
//span[text()='导演:']/../div/a/text()XPath规则教程到此结束,接下来是Jsoup规则教程
Jsoup规则教程
每条视频源规则由多段组成,每段以 @ 间隔,其中每段又由三部分组成,每部分以 . 间隔。示例规则:class.abc.0@tag.a.0@text##被替换内容##替换内容
以如下 html 示例代码来做规则详细说明:
html
<div class="abc">
<a href="https://www.baidu.com">百度</a>
<a href="https://www.qq.com">qq</a>
</div>
<div class="abc">
<div id="weibo">
<a href="https://weibo.com" data-name="自定义属性值">微博</a>
</div>
</div>- 第一段:
class.abc.0,以小数点隔开成三部分- 第一部分
class是选择器类型,该类型支持class、tag、id,class 是 CSS 的类选择器,id 是元素 ID 选择器,tag 是元素标签选择器, - 第二部分
abc是选择器名称 - 第三部分
0是元素位置,0代表第一个元素,如果只有一个元素,则可以省略
- 第一部分
在示例代码内,通过 class.abc.0 取到的元素就是
html
<div class="abc">
<a href="https://www.baidu.com">百度</a>
<a href="https://www.qq.com">qq</a>
</div>如果是 class.abc.1 则取到的元素就是
html
<div class="abc">
<div id="weibo">
<a href="https://weibo.com" data-name="自定义属性值">微博</a>
</div>
</div>- 第二段
tag.a.0是和第一段一样的,都是为了筛选需要的元素,该类规则可以有多段,例如class.abc.0@tag.a.0@tag.a.0,直到筛选到需要的元素。
在示例代码内,通过 class.abc.1@id.weibo 取到的元素就是
html
<div id="weibo">
<a href="https://weibo.com" data-name="自定义属性值">微博</a>
</div>以此类推,通过 class.abc.1@id.weibo@tag.a 取到的元素就是
html
<a href="https://weibo.com" data-name="自定义属性值">微博</a>- 最后一段
text##被替换内容##替换内容,此段为获取内容,支持:text、ownText、href、src、元素的自定义属性,要替换内容就添加##被替换内容##替换内容,如果只是要删除某些文本,只需要写被替换内容即可,##替换内容可以省略。 -text获取此元素及其所有子元素的文本内容 -ownText获取当前元素的文本内容,不获取所有子元素的文本内容 -href超链接的 url -srcimg 等标签的 src 属性 -元素的自定义属性元素自定义的属性
使用 class.abc.1@id.weibo@tag.a@text 获得的是 微博
使用 class.abc.1@id.weibo@tag.a@text##微博##weibo 获得的是 weibo
使用 class.abc.1@id.weibo@tag.a@hrf 获得的是 https://weibo.com
使用 class.abc.1@id.weibo@tag.a@data-name 获得的是 自定义属性值
使用 class.abc.1@id.weibo@tag.a@data-name##自定义 获得的是 属性值
发现规则说明
💡提示
发现 Url 筛选规则,是用于影视分类和属性筛选之用,该部分的规则格式是 json 格式,其中顶层的 filter 的优先率高于子分类的 filter。如果站点的每个分类的过滤条件一致,可定义顶层的 filter 规则,省略每个子分类的 filter 规则
发现 Url 筛选规则的格式
json
{
"url": "此处填写影视列表筛选页URL地址",
//参数名映射,用于处理伪静态Url参数,动态Url或参数名一致时可省略
"mapping":{
"id": "newid", //分类和子分类
"type": "newtype", //类型
"area": "newarea", //地区
"year": "newyear", //年份
"page": "newpage", //分页
"sort": "by" //排序
},
"classify": [
{
"id": 1, //若Url采用了伪静态隐藏了ID,则设为0或省略,然后使用伪静态别名
"alias": "dianying", //伪静态别名,可忽略
"name": "电影",
"subClassify": [
{
"id": 6, //若使用alias别名,id可省略
"alias": "dongzuo", //别名,一般是在伪静态隐藏了分类时设置,可忽略
"name": "动作片"
},
{
"id": 7, //若使用alias别名,id可省略
"alias": "xiju", //别名,一般是在伪静态隐藏了分类时设置,可忽略
"name": "喜剧片"
}
], //可省略
"filter": {} //可省略
}
],
"filter": {}, //可省略
"defaultSort": "time", //默认排序
"sort": [
{
"name": "按时间", //显示的名称
"value": "time" //排序参数值
},
{
"name": "按热度",
"value": "hits"
},
{
"name": "按评分",
"value": "score"
},
]
}发现 Url 筛选规则的 url 参数说明:
固定参数:{{id}} {{area}} {{type}} {{year}} {{page}} {{sort}}
{{id}}分类 classify 和子分类 subClassify 的 ID{{area}}地区,例如:国内,欧美等{{type}}影片类型,例如:喜剧,科幻等{{year}}上映年份{{page}}分页,也就是下一页{{sort}}排序
例如:https://abc.com/show/id/1/area/国内/type/喜剧/year/2022/sort/time/page/1.html 发现 Url 筛选规则只需把对应的值替换为参数即可,可以省略域名部分,得到的规则为: /show/id/{{id}}/area/{{area}}/type/{{type}}/year/{{year}}/sort/{{sort}}/page/{{page}}.html
发现 Url 筛选规则的 classify 规则说明:
classify 是表示影视分类,classify 的值是一个数组,单个分类的 JSON 对象格式为:
json
{
"id": 1,
"name": "电影",
"alias": "dianying",
"subClassify": [],
"filter": {},
"defaultSort": "time",
"sort": [
{
"name": "按时间",
"value": "time"
},
{
"name": "按热度",
"value": "hits"
}
]
}id 是分类的 ID,name 是分类名称,subClassify 是该分类的子分类,filter 为筛选条件组。
classify 里的 id 和 name 是必须有的,alias是在Url采用了伪静态隐藏了主分类ID时使用,subClassify 和 filter 可以省略。例如:
json
{
"id": 1,
"alias": "dianying",
"name": "电影"
}subClassify 格式:
json
[
{
"name": "喜剧片",
"alias": "xijupian"
},
{
"name": "动作片",
"alias": "dongzuopian"
}
]subClassify 是一个数组,单个子分类格式为:
json
{
"id": 6,
"alias": "dongzuo",
"name": "动作片"
}id 是子分类的 ID,name 是子分类名称。如果子分类是以 name 进行筛选,id 可省略。
filter 的格式:
json
{
"type": [],
"area": [],
"year": []
}filter 可以只包含 type area year 中的一个或者几个。
filter 里的每个元素都是一个数组,数组类型和subClassify一致,如果筛选条件时用的是 name 值或者 alias 别名,id 可省略。
将以上的各部分规则合并起来,完整的筛规则选格式如下:
json
{
"url": "此处填写影视列表筛选页URL地址",
"classify": [
{
"id": 1,
"name": "电影",
"subClassify": [
{
"id": 6,
"name": "动作片"
},
{
"id": 7,
"name": "喜剧片"
}
],
"filter": {
"type": [
{
"id": 1, // 如果筛选值是跟name一致,id可省略
"name": "喜剧"
},
{
"id": 2,// 如果筛选值是跟name一致,id可省略
"name": "爱情"
}
],
"area": [
{
"id": 18,// 如果筛选值是跟name一致,id可省略
"name": "大陆"
},
{
"id": 0,// 如果筛选值是跟name一致,id可省略
"name": "香港"
}
]
}
},
{
"id": 2,
"name": "电视剧",
"subClassify": [],
"filter": {}
},
{
"id": 3,
"name": "综艺"
}
],
"defaultSort": "time",
"sort": [
{
"name": "按时间",
"value": "time"
},
{
"name": "按热度",
"value": "hits"
}
]
}播放规则说明
其中 Js变量 可以使用Jsoup规则格式也可以使用XPath规则格式, Url正则 为固定格式,单独处理,不在Jsoup和XPath格式之内。例如:
html
<script>
var param = {"a": "a", "nowPlay": "https://a.com/x.html", "nextPlay": ""}
</script>txt
Js变量://script[contains(text(),'param')]/text()
Url正则:(https?).+?(?=".+next)||(https?)##https://www.abc.com/?url=$1txt
Js变量:param@(https?).+?(?=".+next) //格式为:JS变量名.位置@正则表达式
Url正则:(https?)##https://www.abc.com/?url=$1- Url 正则:用来处理播放 URL 的相关正则表达式,如需替换播放 URL 部分内容,可在正则表达式后添加
##替换内容,例如:正则表达式1||正则表达式2||...||正则表达式n##替换内容
💡提示
Url正则里的正则表达式可有多个,按顺序进行处理,每个表达式之间以 || 隔开